3 NLP basics
Language Model
N-gram: distribution of next word is a categorical conditioned on previous N-1 words,
I visited San ____
- Unigram: mutual indepedent
- Bigram: P(w|San)
- 3-gram: P(w|visited San)
Smoothing
- Add-1 estimate(Laplace Smoothing):
- Backoff: use trigram if you have good evidence, otherwise bigram, otherwise unigram
- Interpolation: mix unigram, bigram, trigram
Perplexity: inverse probability of the test set, normalized by the number of words
Word Embedding
Problems with tf-idf(Term frequency-Inverse document frequency)
- long(length = 20,000 to 50,000)
- sparse(most elements are zero)
where
Word2Vec
Dense vectors
- Short vectors may be easier to use as features in machine learning (fewer weights to tune)
- Dense vectors may generalize better than explicit counts
- Dense vectors may do better at capturing synonymy(car and automobile)
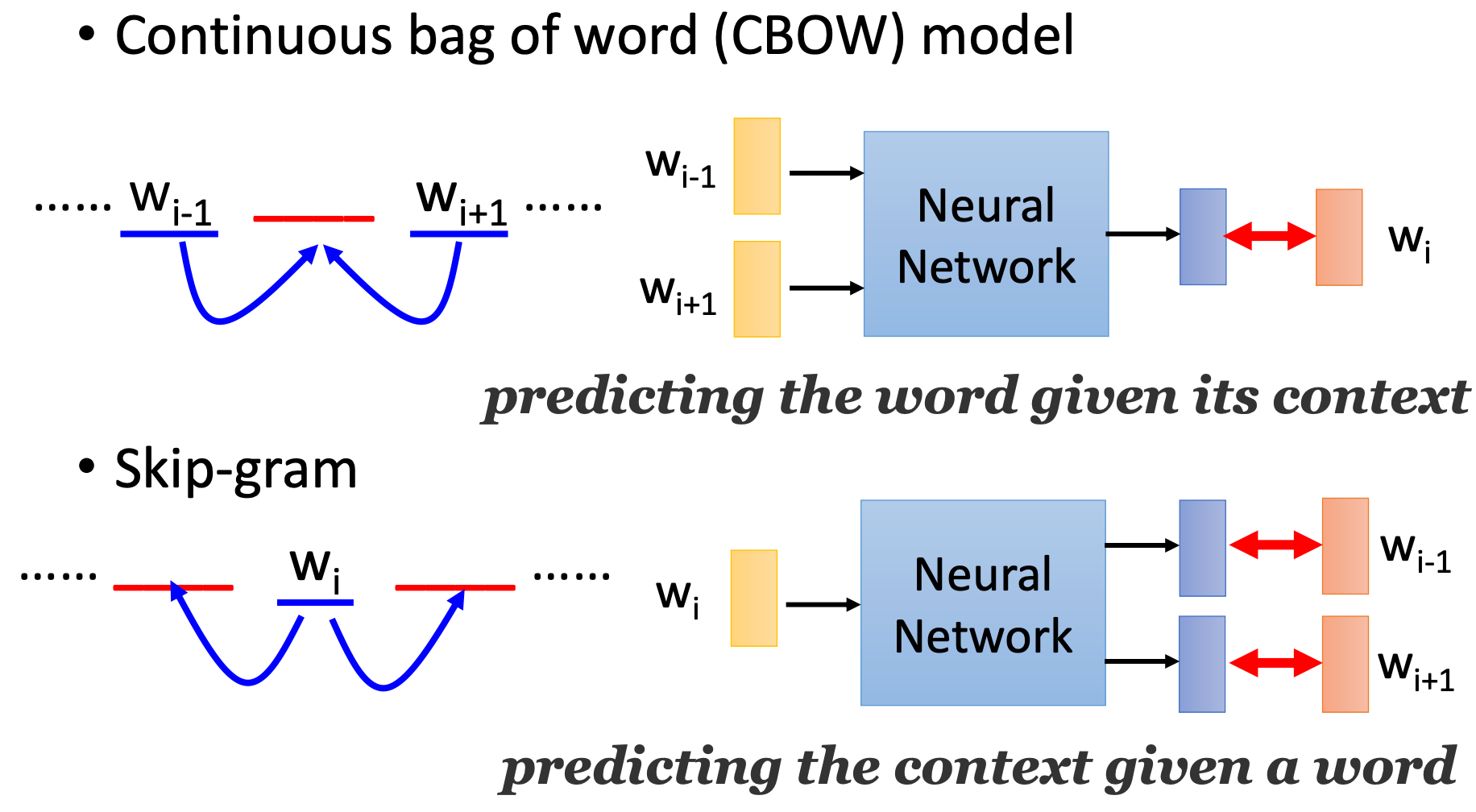
Negative Sampling
- Start with V random d-dimensional vectors as initial embeddings
- Train a classifier based on embedding similarity
- Take a corpus and take pairs of words that co-occur as positive examples
- Grab k negative examples for each target word
- Train the classifier to distinguish these by slowly adjusting all the embeddings to improve the classifier performance
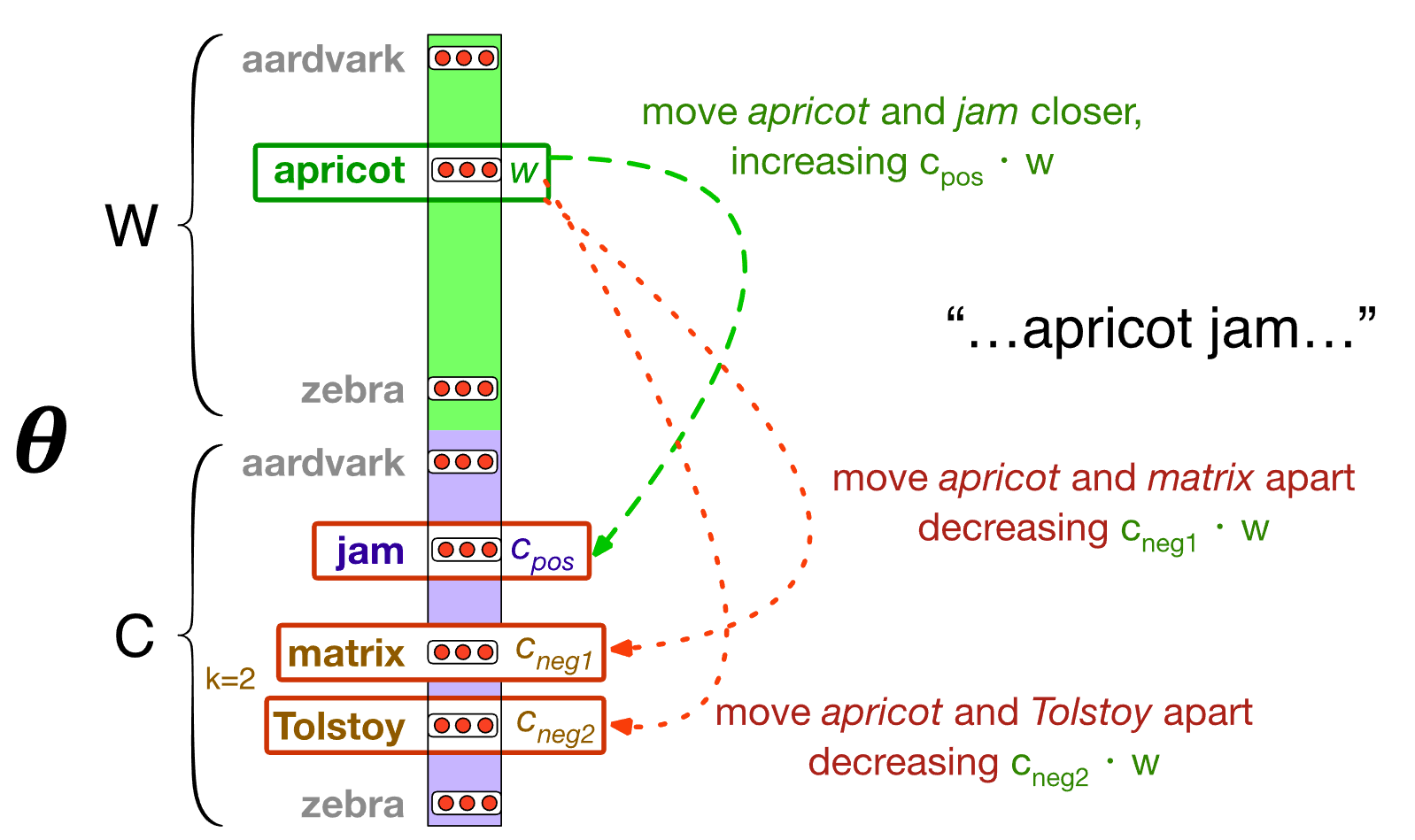
Where:
- : Number of negative samples.
- : Input embedding of the target word .
- : Output embedding of the positive context word .
- : Output embedding of a negative context word .
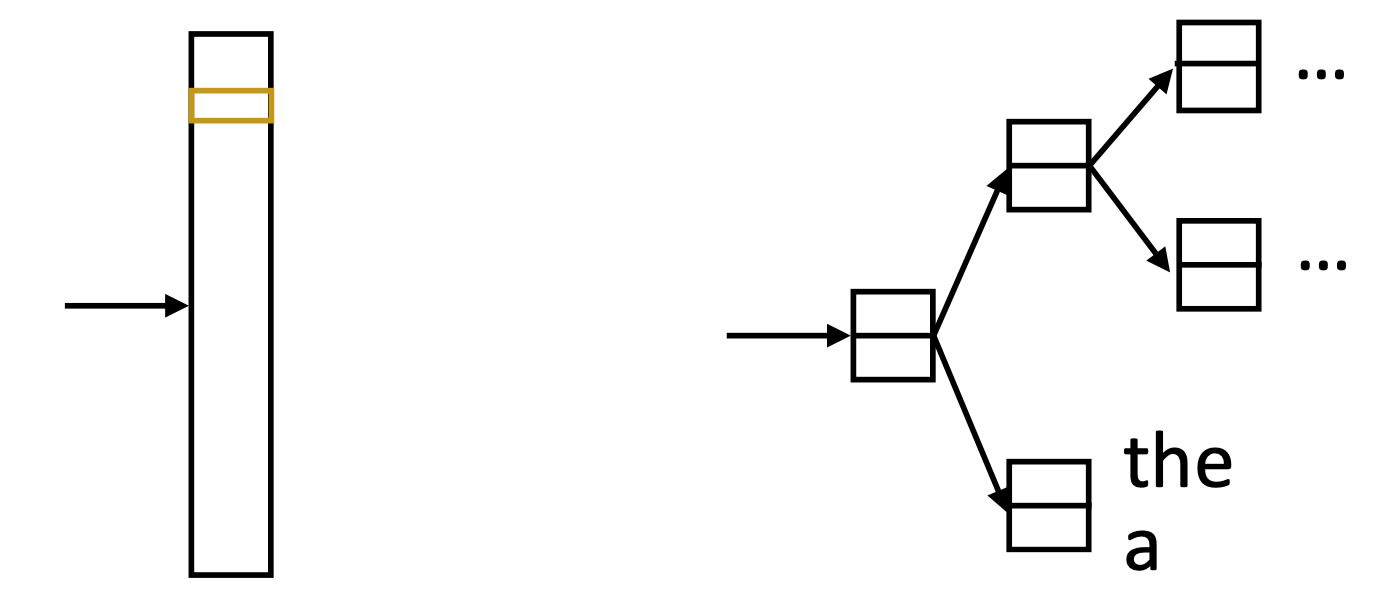
Hierarchical Softmax
- Matmul + softmax over |V| (# of words) is very slow to compute for CBOW and SG
- Huffman encode vocabulary, use binary classifiers to decide which branch to take: log(|V|)
Golve
Construct a Global Vectors for Word Representation
Efficiency
- Pros: Efficient for large corpora
- Cons: Relatively slow for small or medium corpora
Effectiveness
- It is a kind of aggregated word2vec/CBOW
- word2vec mainly focuses on local sliding windows
- GloVe is able to combine global and local features
- More flexible with the values in matrix
- log, PMI variants, ... many tricks can be played!
Sequence labeling
Part of Speech Tagging

Named Entity Recognition
Most common
- PER (Person): “Marie Curie”
- LOC (Location): “New York City”
- ORG (Organization): “Stanford University”
- GPE (Geo-Political Entity): "Boulder, Colorado"
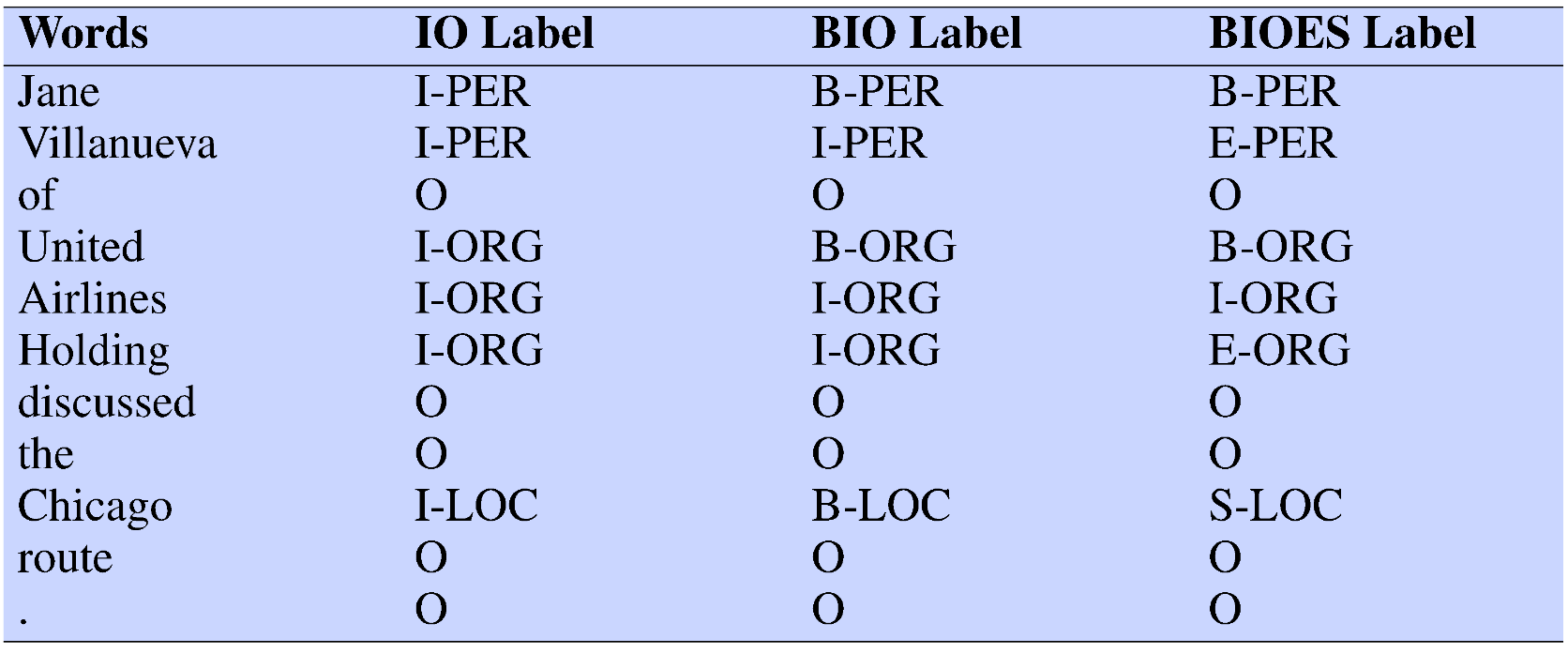
IO vs BIO vs BIOES
HMM(Hidden Markov Models)
Tag assignment:
Bigram Assumption:
where
- Transition Probabilities : The probability of transitioning from one state to another.
- Emission Probabilities : The probability of observing a specific observation given a state.