2 Deep Learning
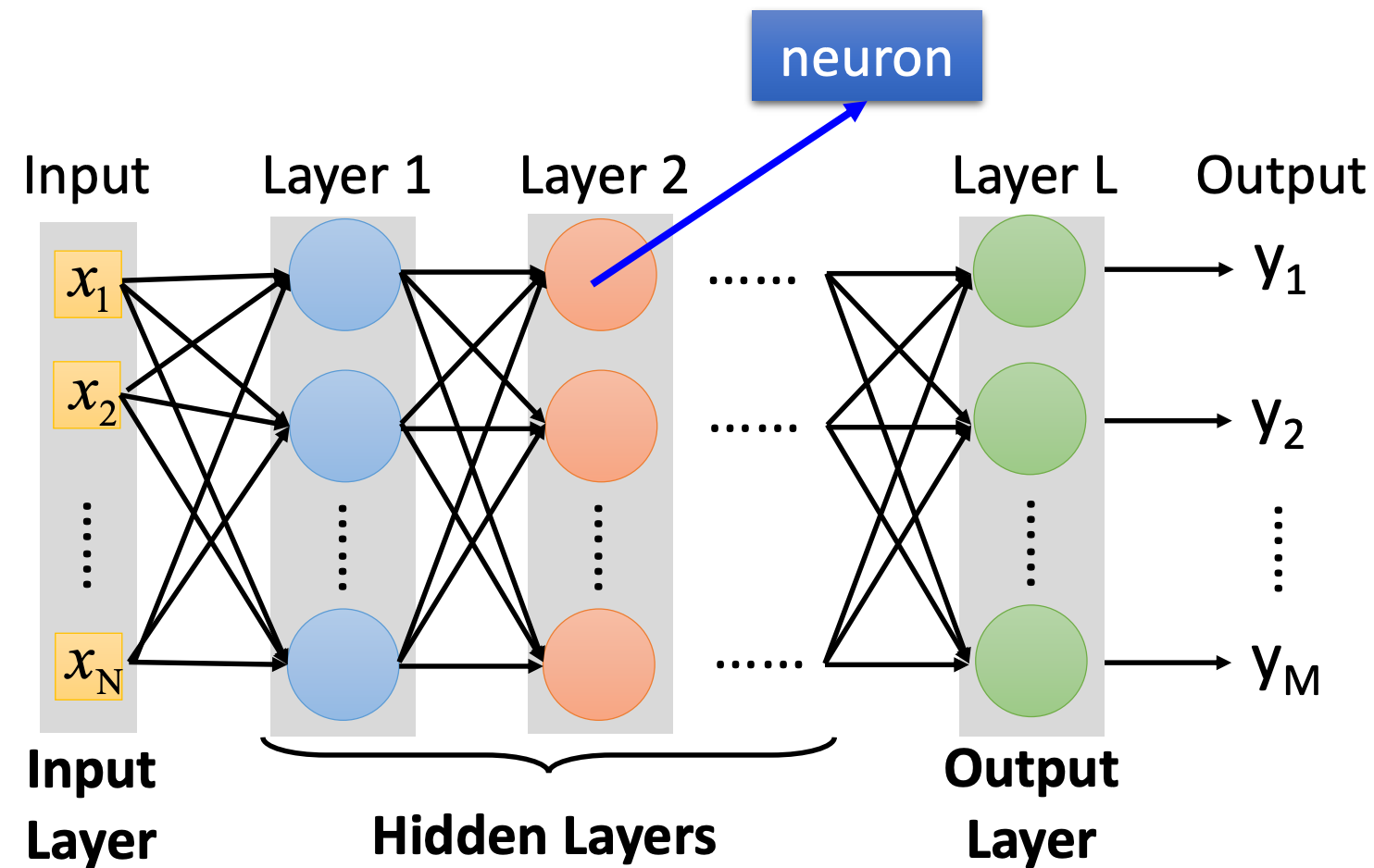
Neural Network
Feed Forward Network
- Each perceptron in one layer is connected to every perceptron on the next layer
- Deep = Many hidden layers
- Last layer still logistic regression
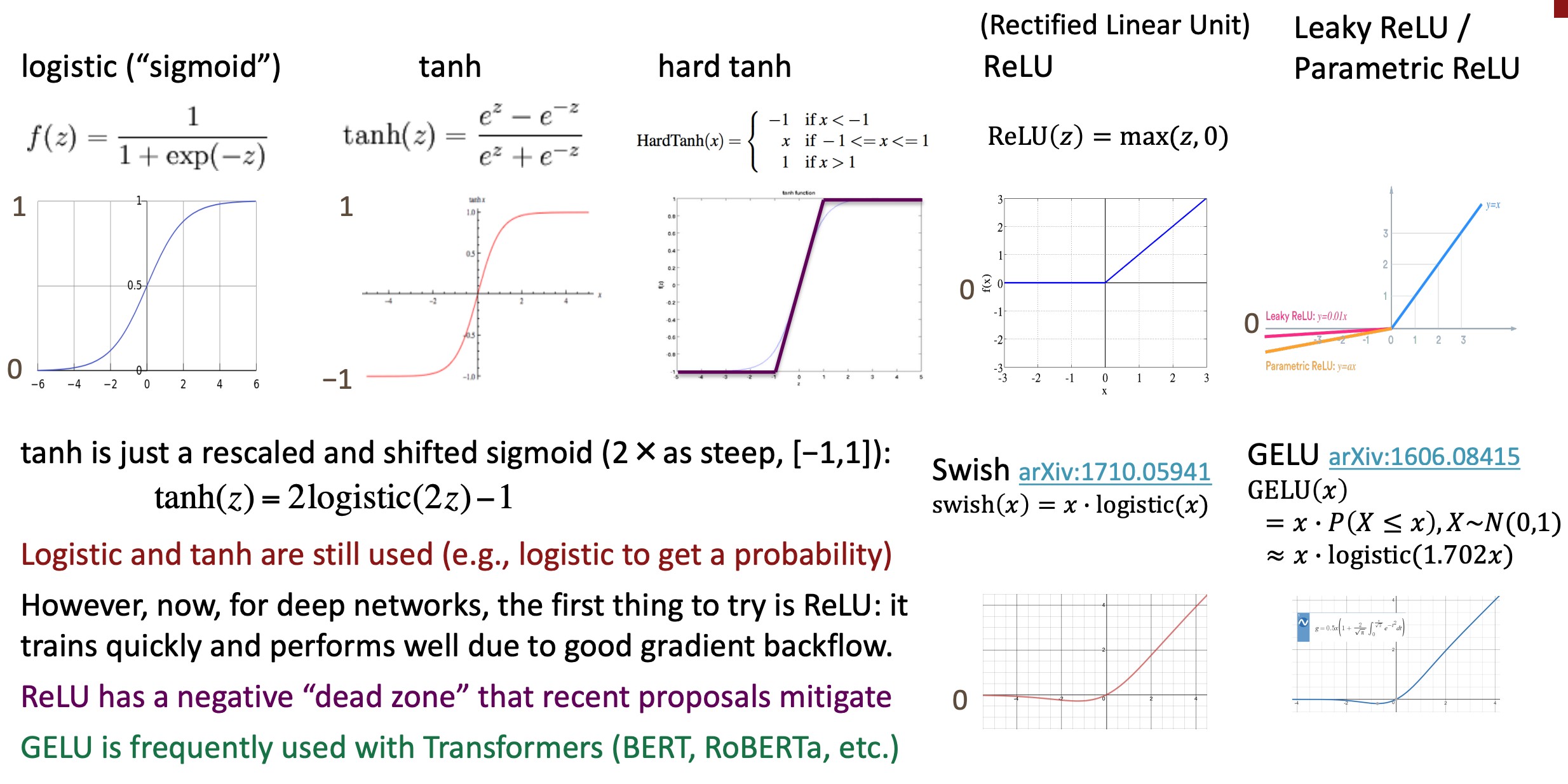
Perceptron(Neuron) , f is an activation function
- Identity: Linear Regression
- Sigmoid: Logistic Regression
One can stack perceptron to a Multi-layer perceptron(MLP)
Activation functions
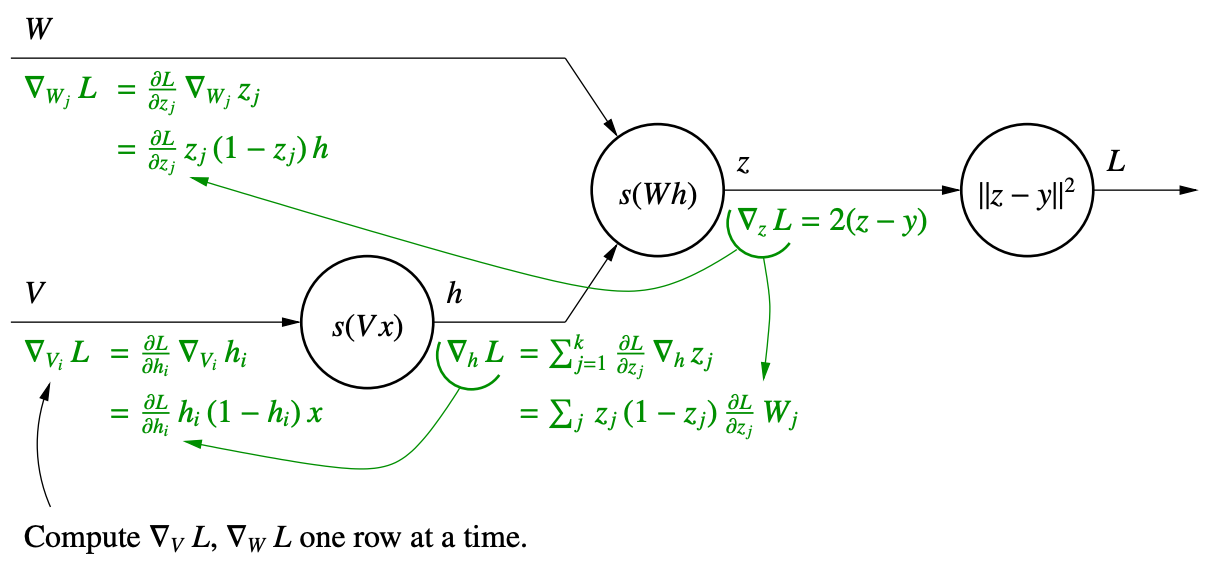
Feedforward and Backpropagation
- One forward pass: Compute all the intermediate output values
- One backward pass: Follow the chain rule to calculate the gradients at each layer, the calculate the product
Chain rule:
CNN
Why CNN for image:
- Some patterns are much smaller than the whole image
- The same patterns appear in different regions
- Subsampling the pixels will not change the object
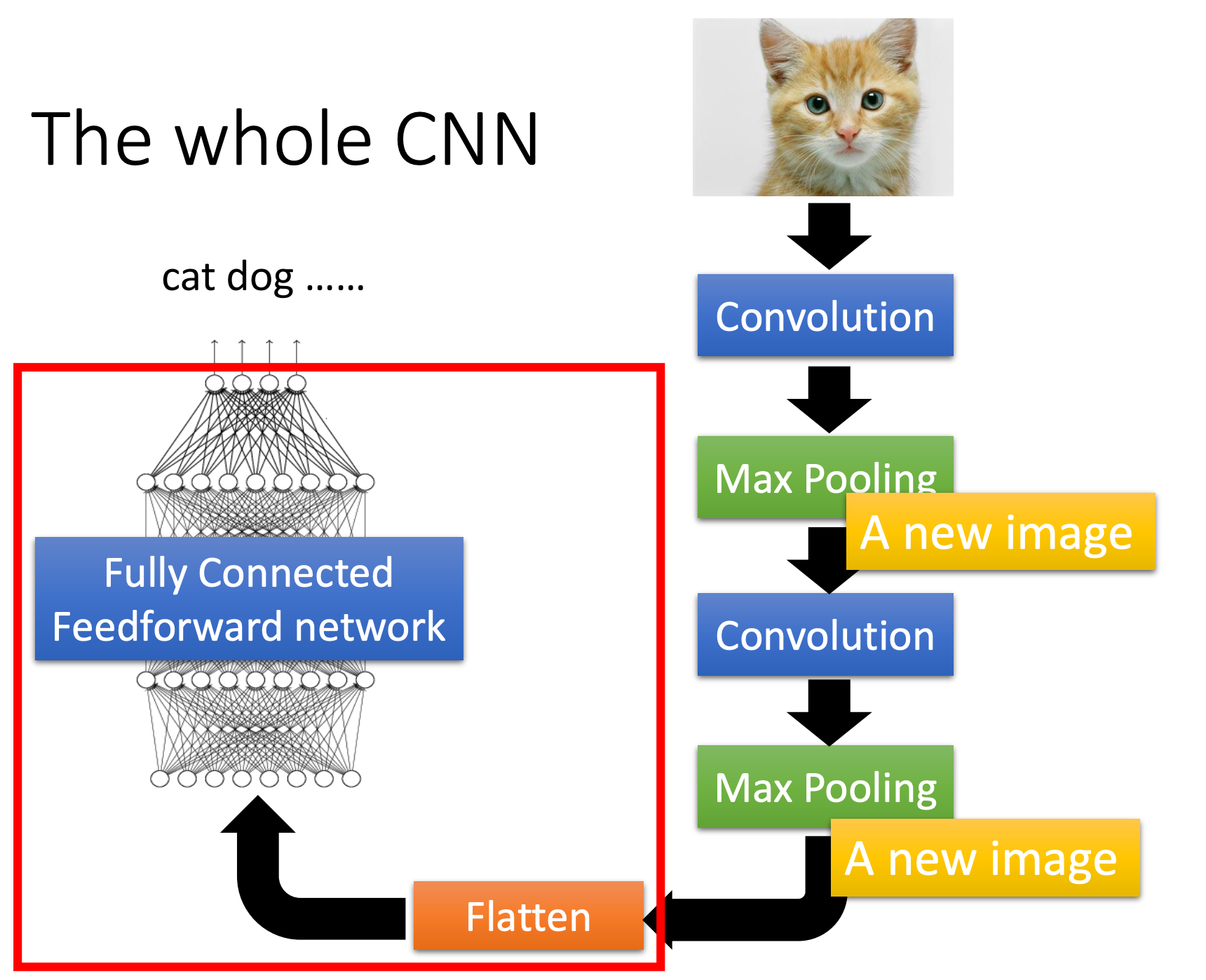
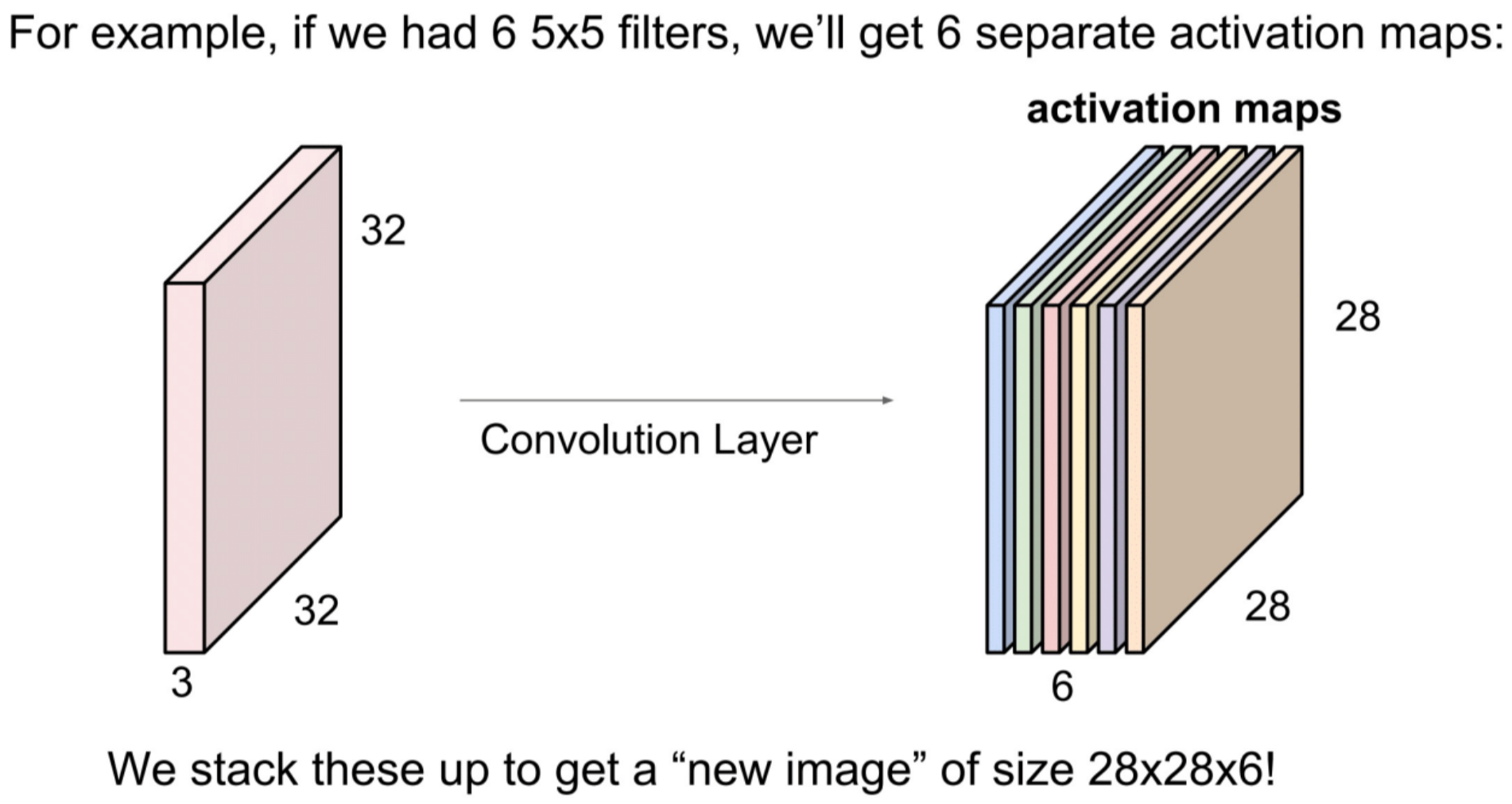
Convolution Layer
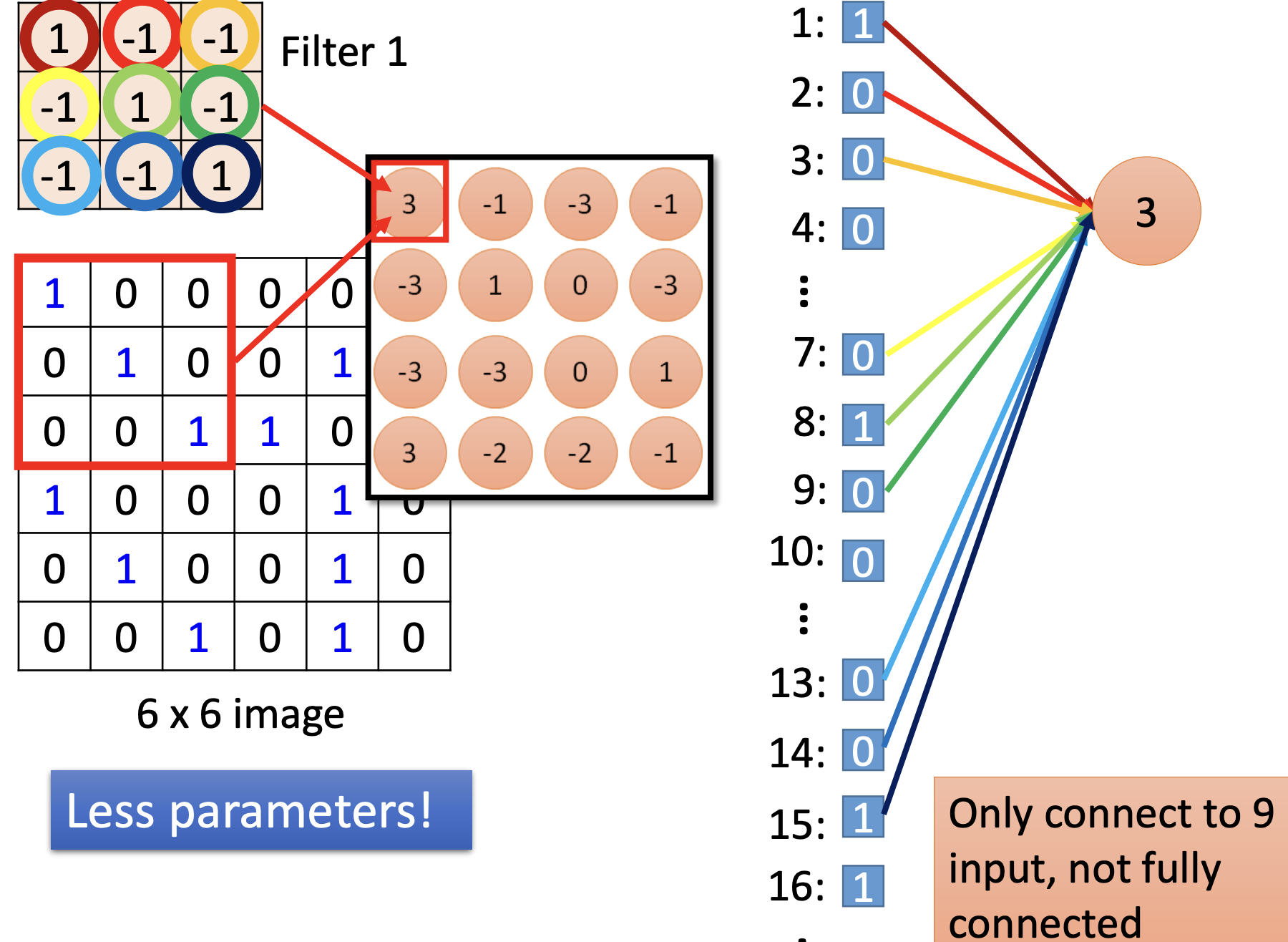
Convolutional Filters

One can stack convolution filters into a new tensor, each filter is a channel
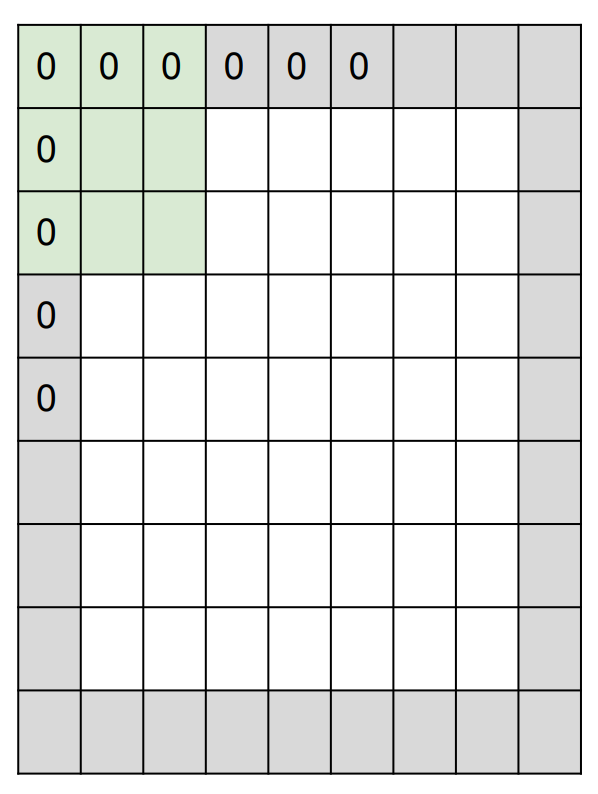
padding: Preserve input spatial dimensions in output activations by padding with n pixels border
Input: tensor
Hyperparameters:
- Number of filters: K, K is usually a power of 2 (32, 64, ...)
- Filter size: , F is usually an odd number (e.g., 3, 5, 7)
- Stride: S, S describes how we move the filter
- Padding size: P
Output: tensor(Get the moving distance first, then add 1)
- W’ = (W – F + 2P) / S + 1
- H’ = (H – F + 2 P) / S + 1
Number of parameters: perform K times :
Usage: using 1*1 filters, we can keep the width and height but increase the number of channels.s
Pooling Layer
We can use Pooling as Subsampling(Downsampling)
Input: tensor
Hyperparameters:
- Filter size:
- Stride: S
Output: tensor
- W' = (W – F) / S + 1
- H’ = (H – F) / S + 1
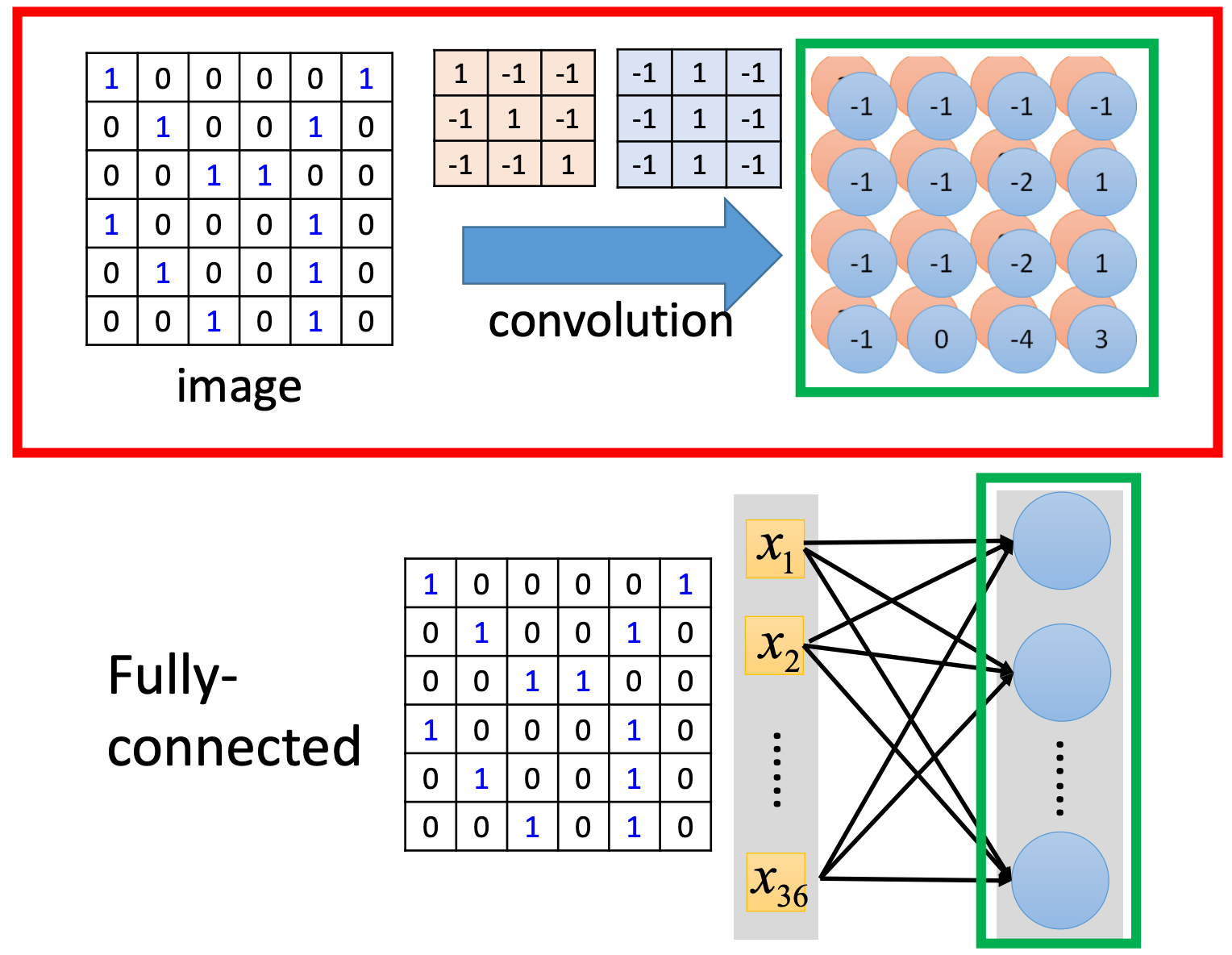
Fully Connected Layer
Flatten
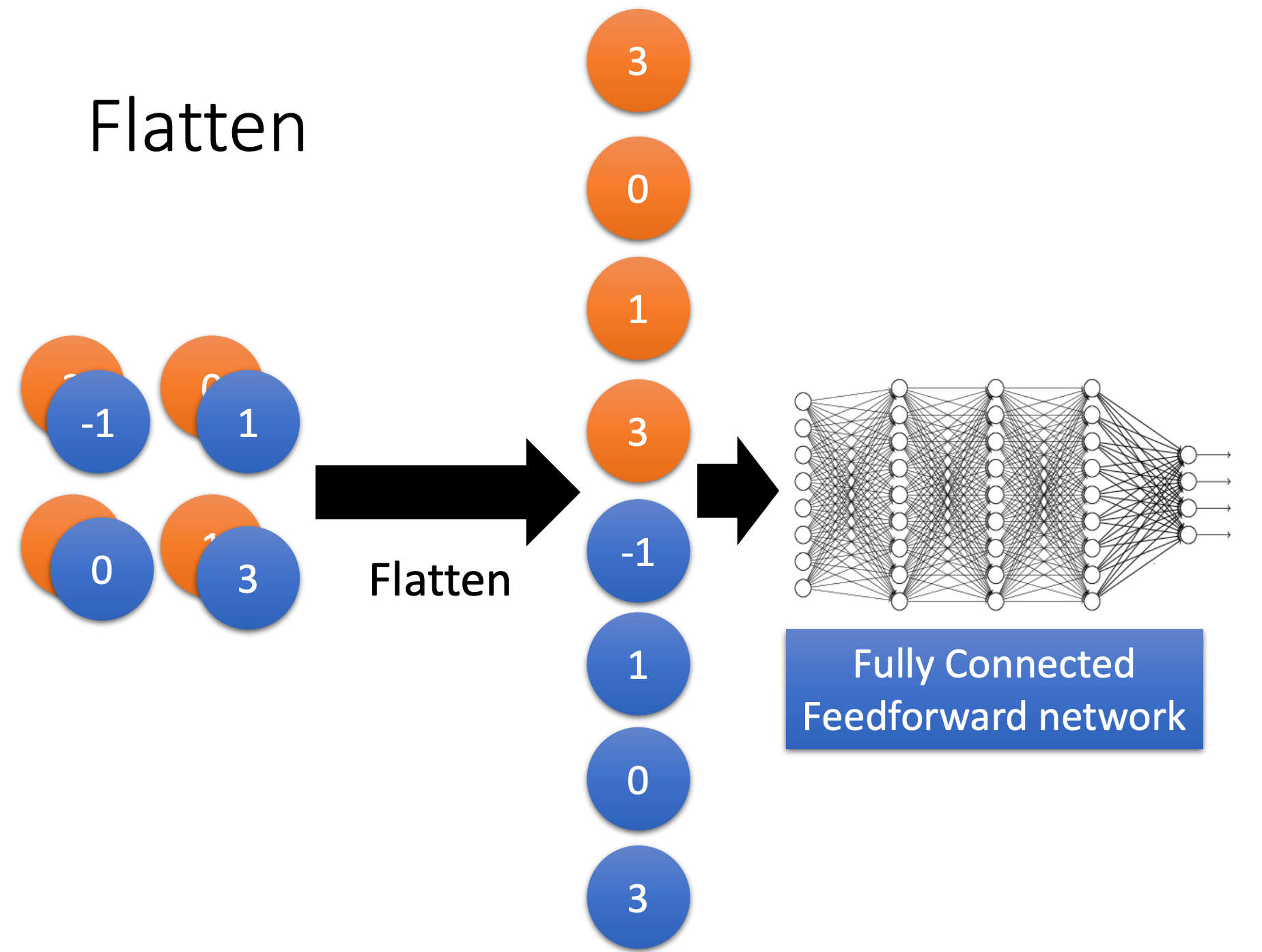
Convolution vs Fully connected
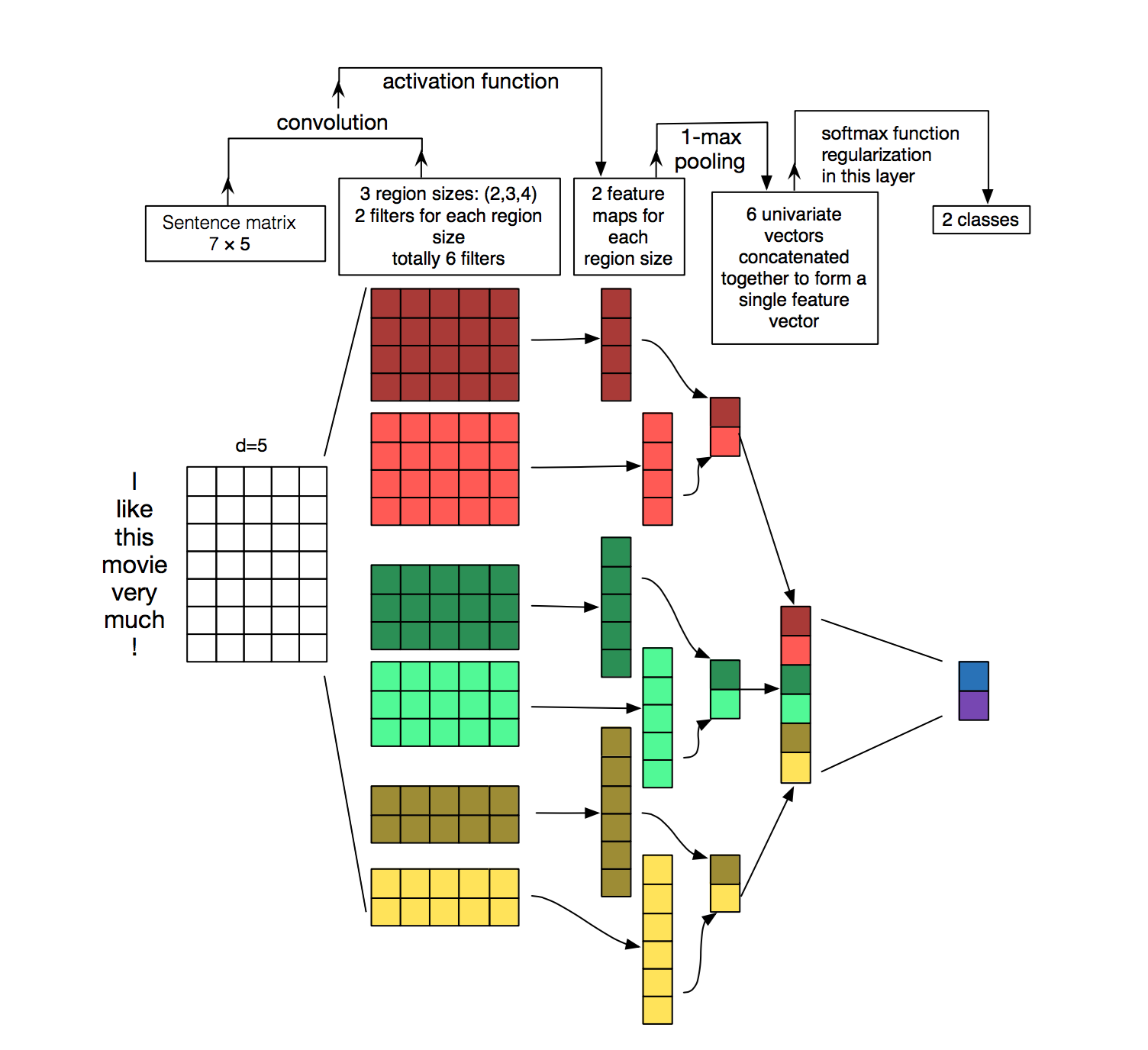
CNN for NLP
- kernel size: the other dimension not mentioned, e.g.
- parallel filters to get different views of the data that can be computed in parallel
RNN
Recurrent Neural Networks: Apply the same weights W repeatly
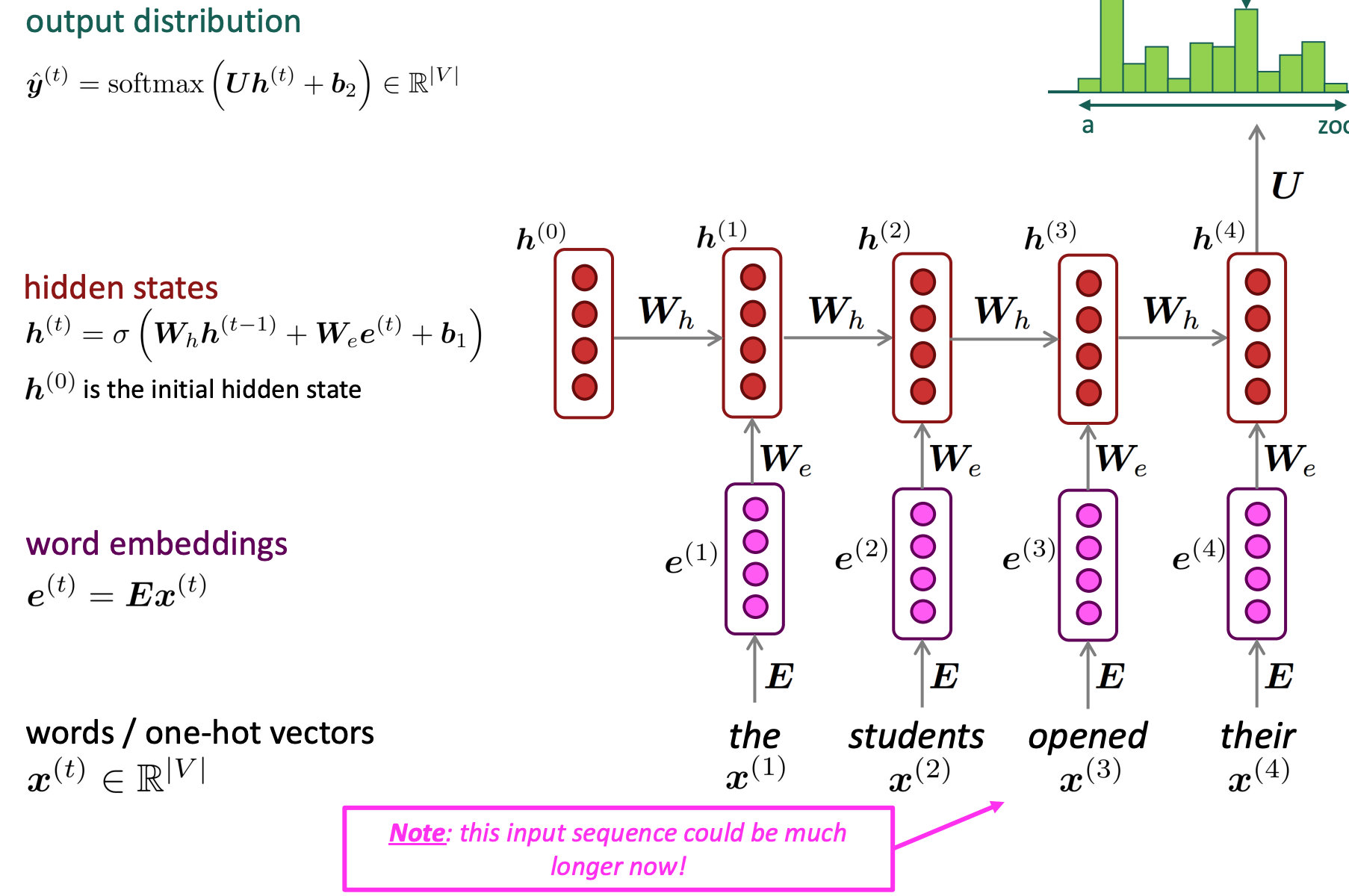
Advantages:
- Can process any length input
- Computation for step t can (in theory) use information from many steps back
- Model size doesn’t increase for longer input context
- Same weights applied on every timestep, so there is symmetry in how inputs are processed
Disadvantages:
- Recurrent computation is slow
- In practice, difficult to access information from many steps back
Vanishing and Exploding gradients
Vanishing gradients: model weights are updated only with respect to near effects, not long-term effects.
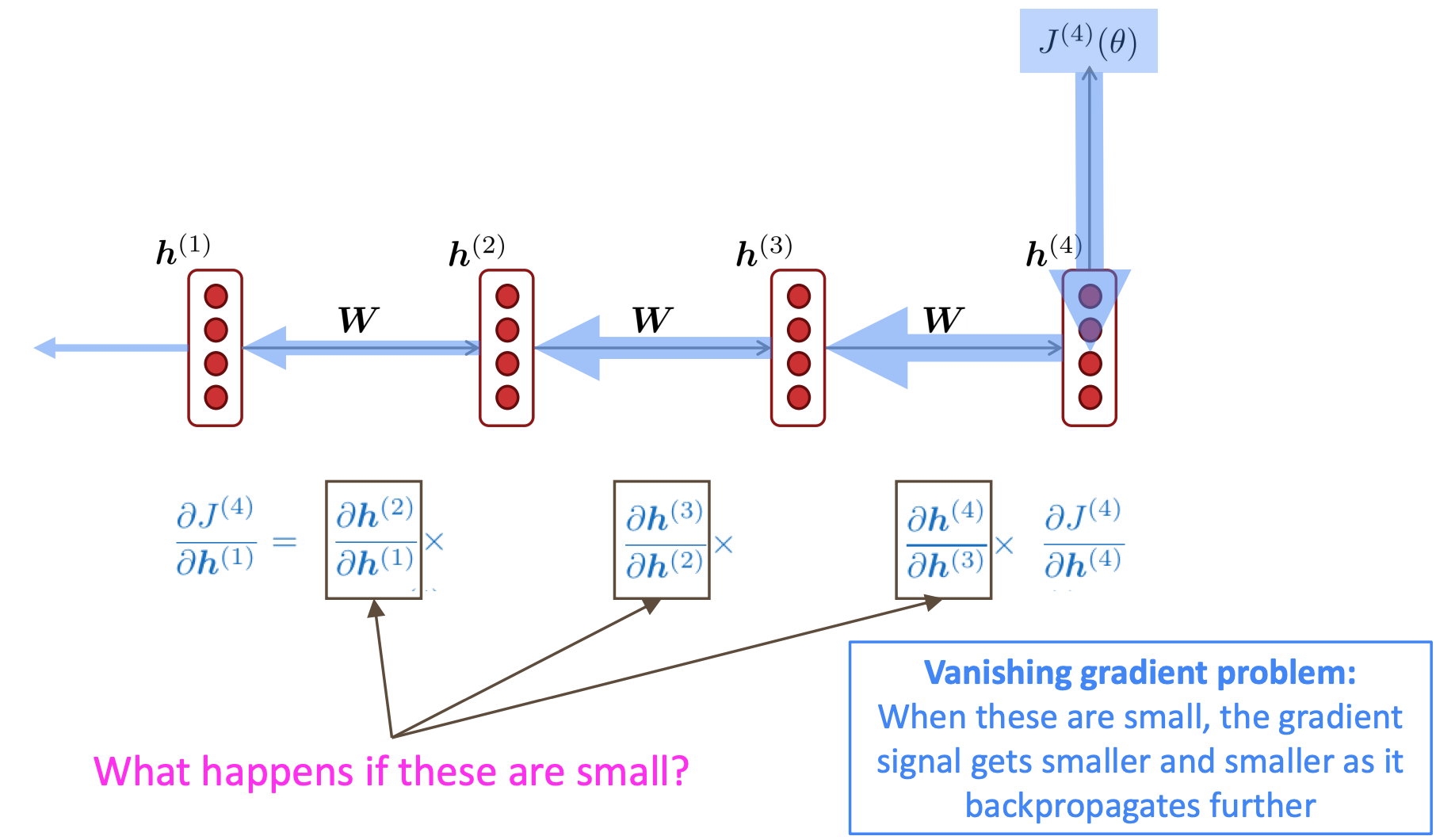
Exploding gradients: If the gradient becomes too big, then the SGD update step becomes too big. We take too large a step and reach a weird and bad parameter configuration.
Solution1: LSTM
Long Short-Term Memory RNN
On step t, there is a hidden state and a cell state
- The cell stores long-term information
- The LSTM can read, erase(forget), and write information from the cell
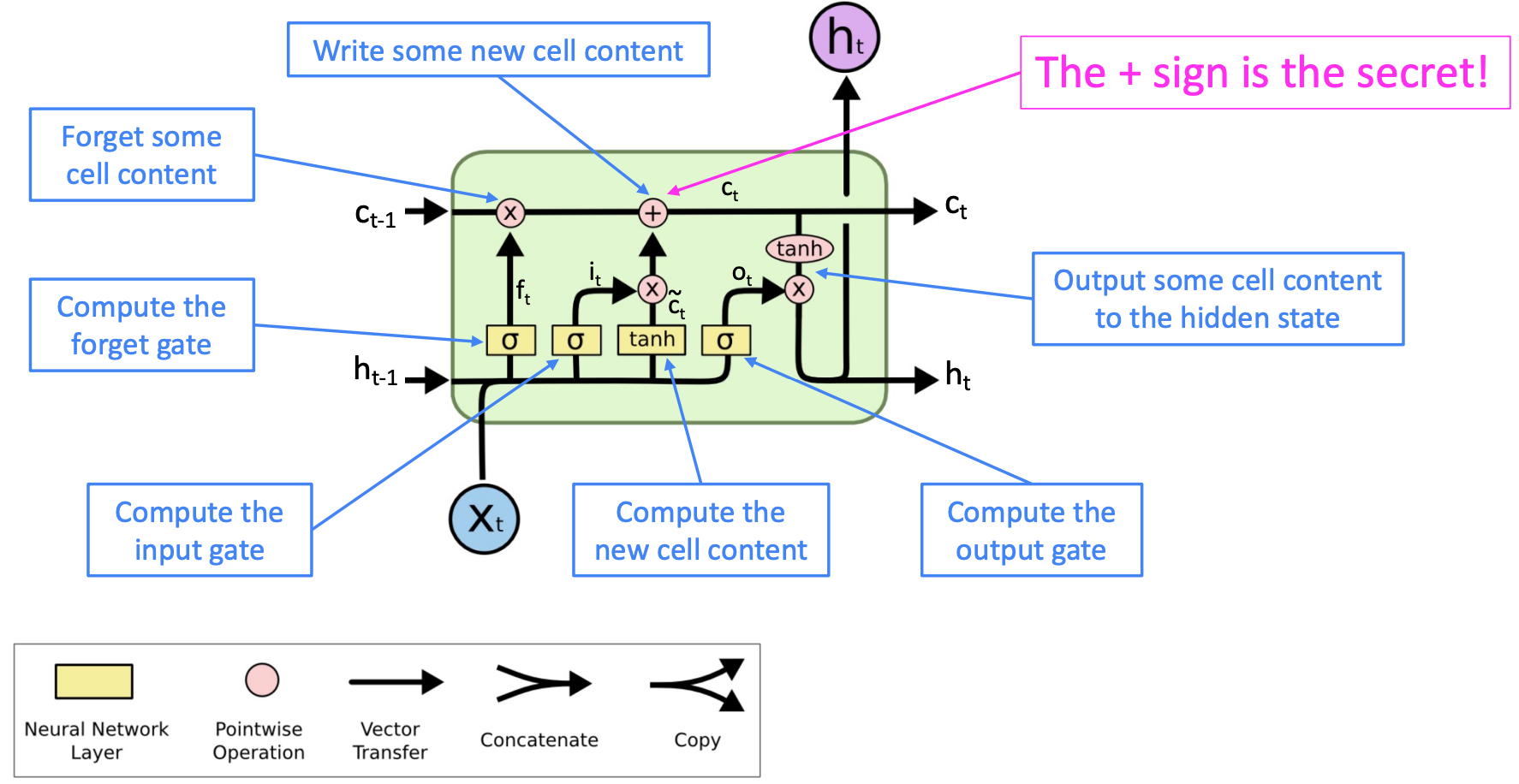
The LSTM architecture makes it much easier for an RNN to preserve information over many timesteps.
e.g., if the forget gate is set to 1 for a cell dimension and the input gate set to 0, then the information of that cell is preserved indefinitely.
Solution2: Other techniques
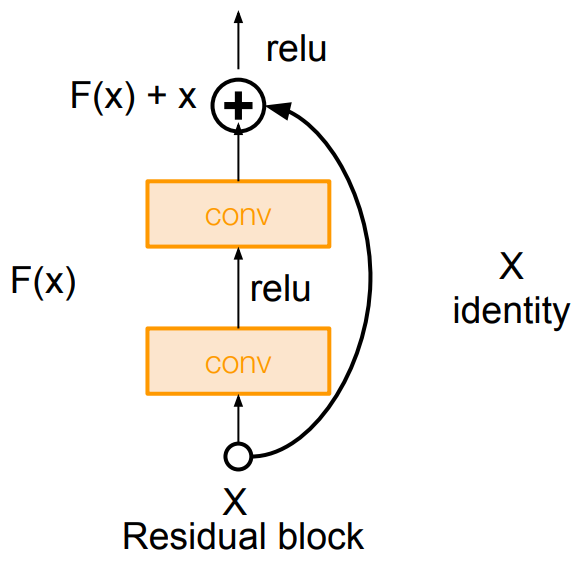
ResNet
The identity connection preserves information by default
Skip connection:
Say, halfway through a normal network, the activations are informative enough to classify the inputs well, but our chosen network still has more layers after that.
We can set weights to be zero(F(x) = 0), now the blocks could easily learn the identity function or small updates
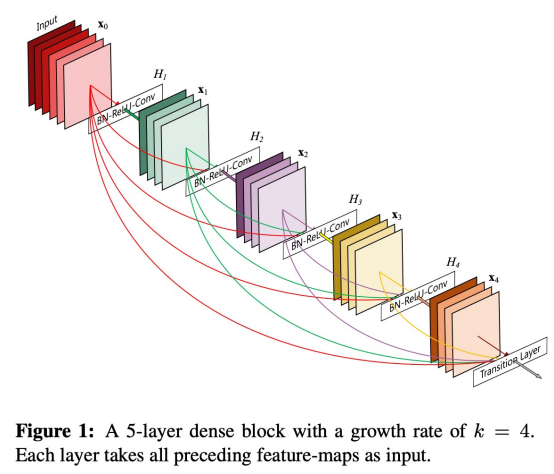
DenseNet
Directly connect each layer to all future layers
Bidirectional and Multi-layer RNNs
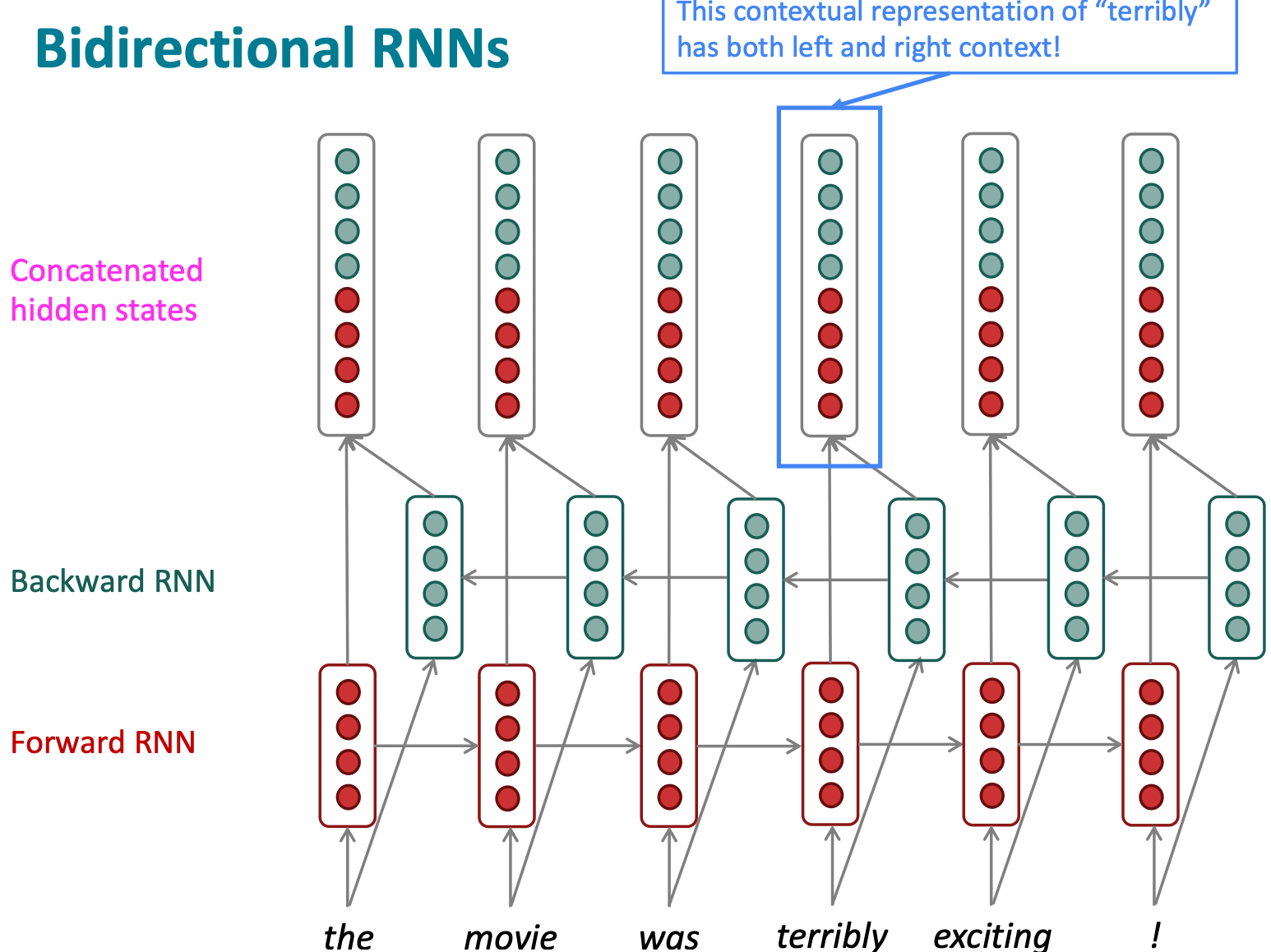
RNN could be a simple RNN or LSTM computation
Forward: RNN
Backward: RNN
Concatenated hidden states:
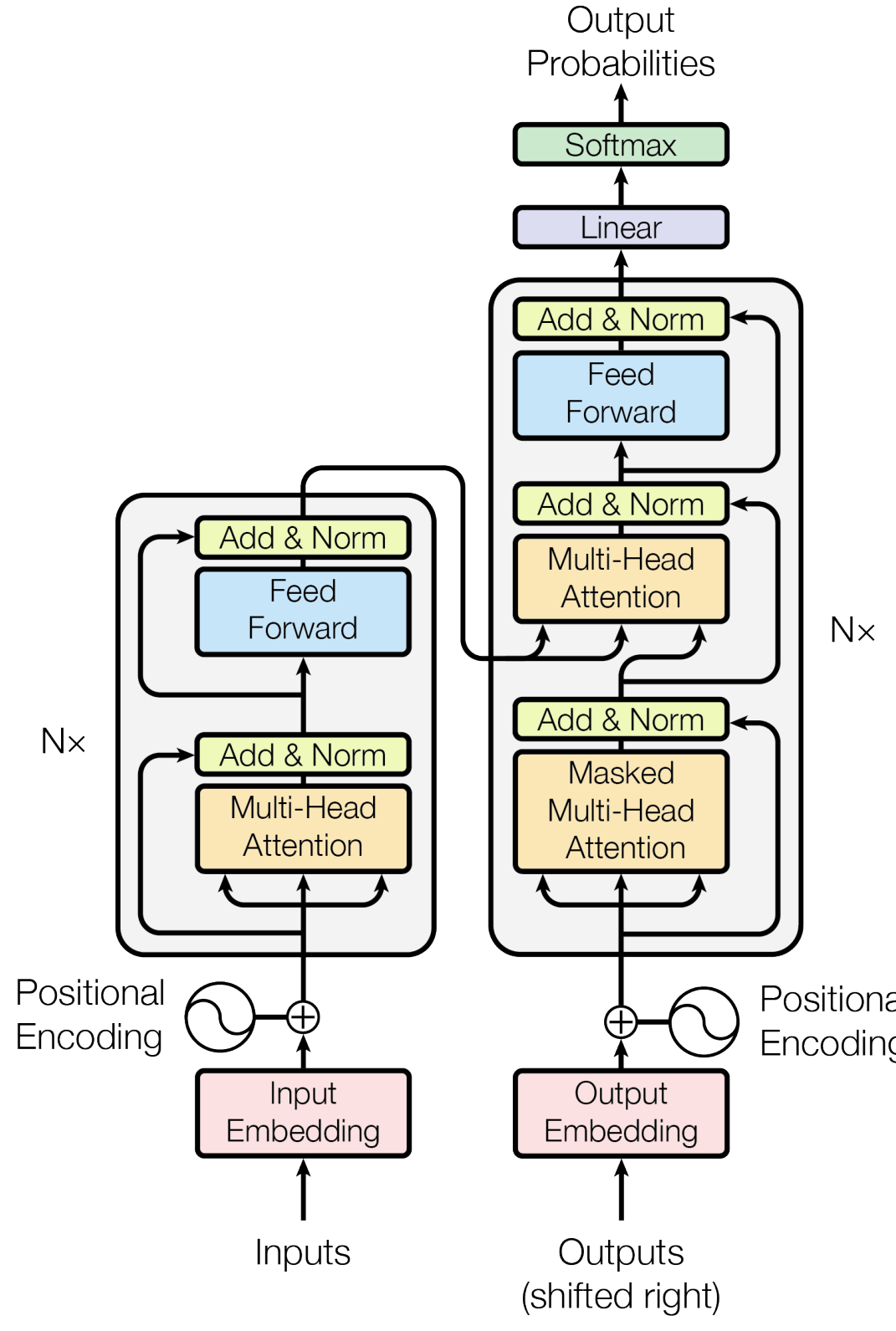
Transformer
Problems with CNN/RNN
- Out of vocabulary
- Solution: Tokenization with sub-words(e.g. ("h", "u", “man”))
- Non-contextual embeddings
- Non-attention
- Sequentiality
- Solution: include sequential information(Positional embedding)
Architecture
Attention
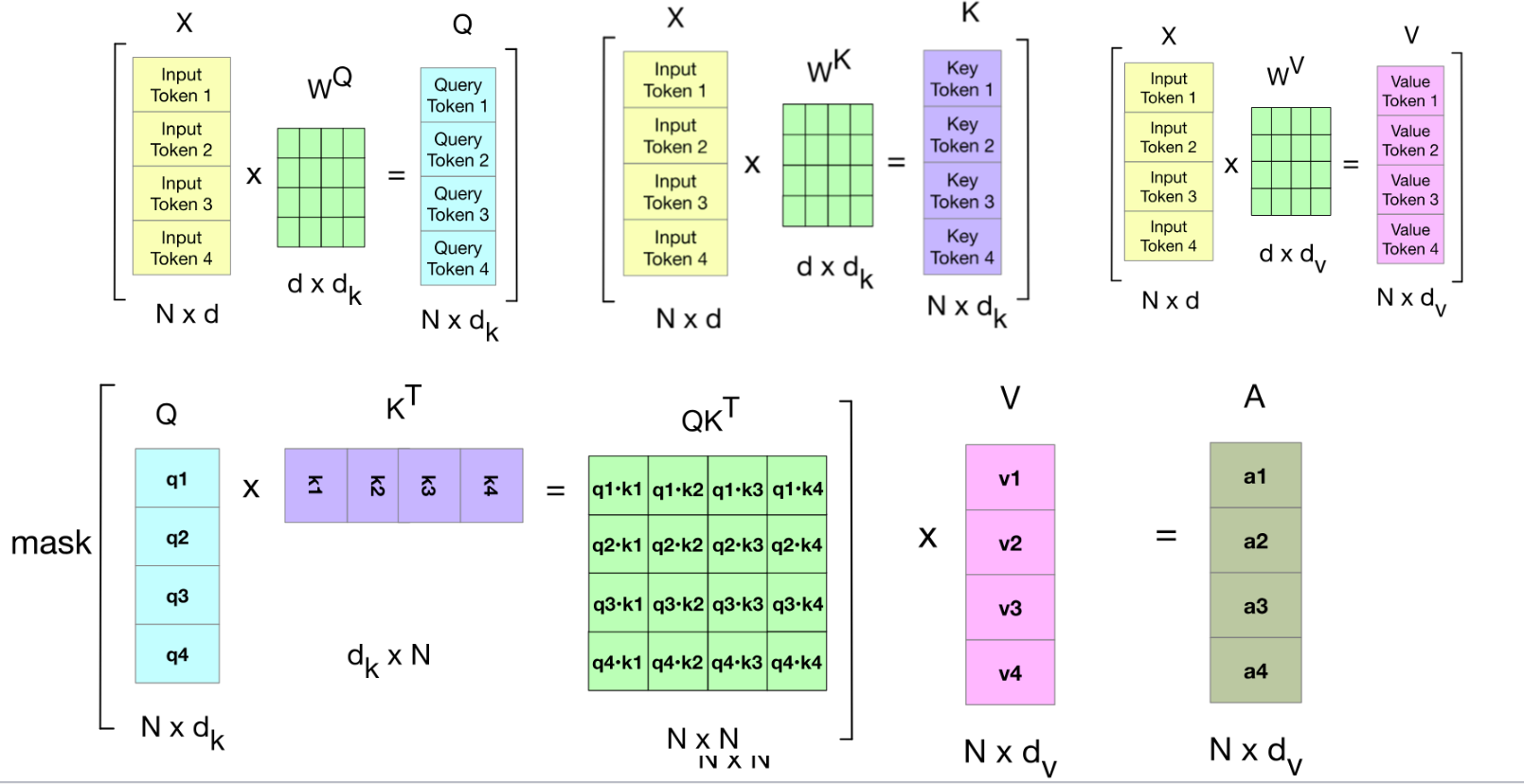
- Self-Attention:
- Cross-Attention: comes from one sequence (e.g., decoder), and come from another sequence (e.g., encoder).
Overfitting
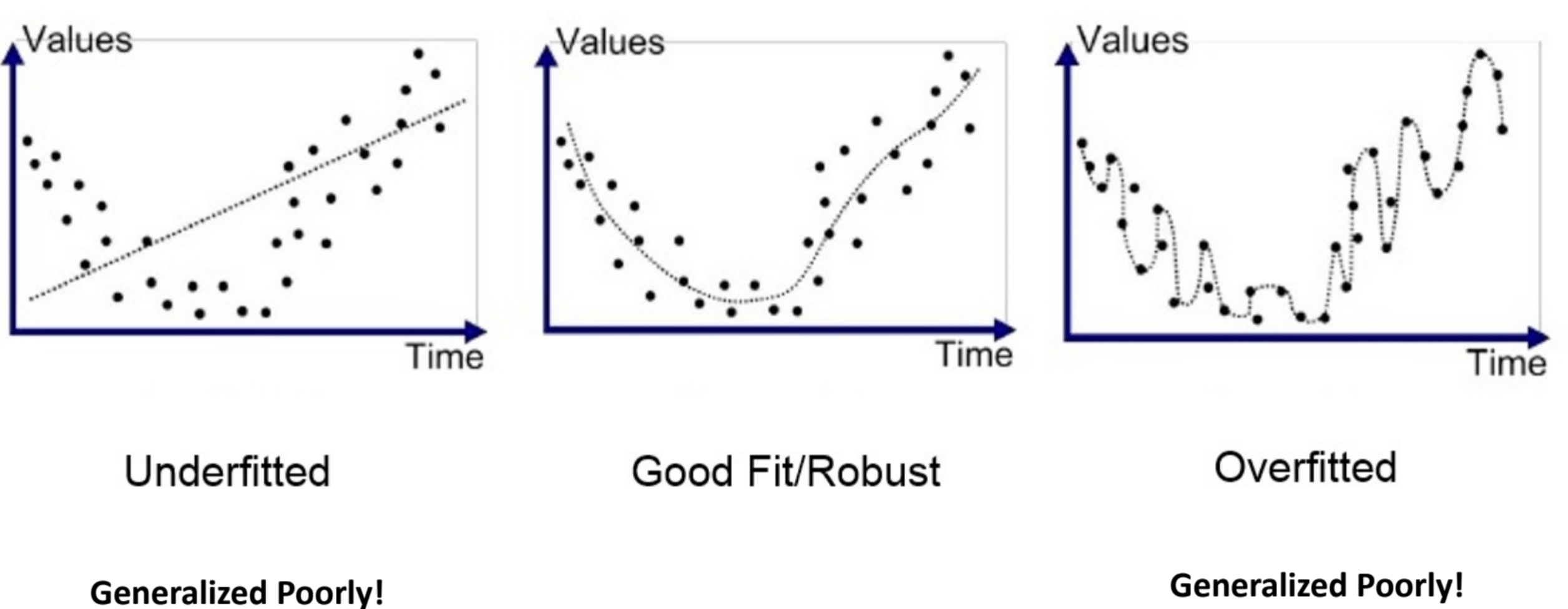
Early Stop
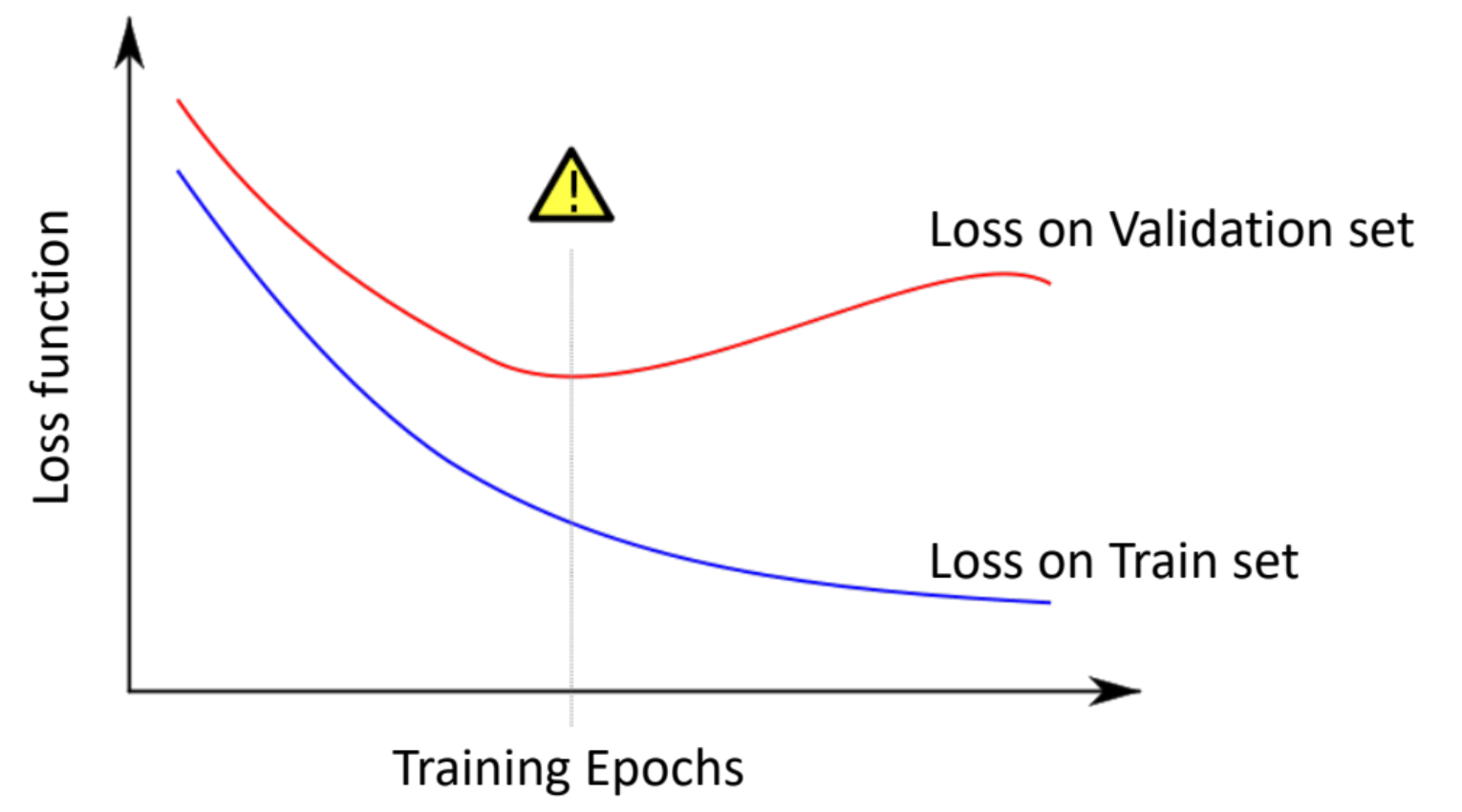
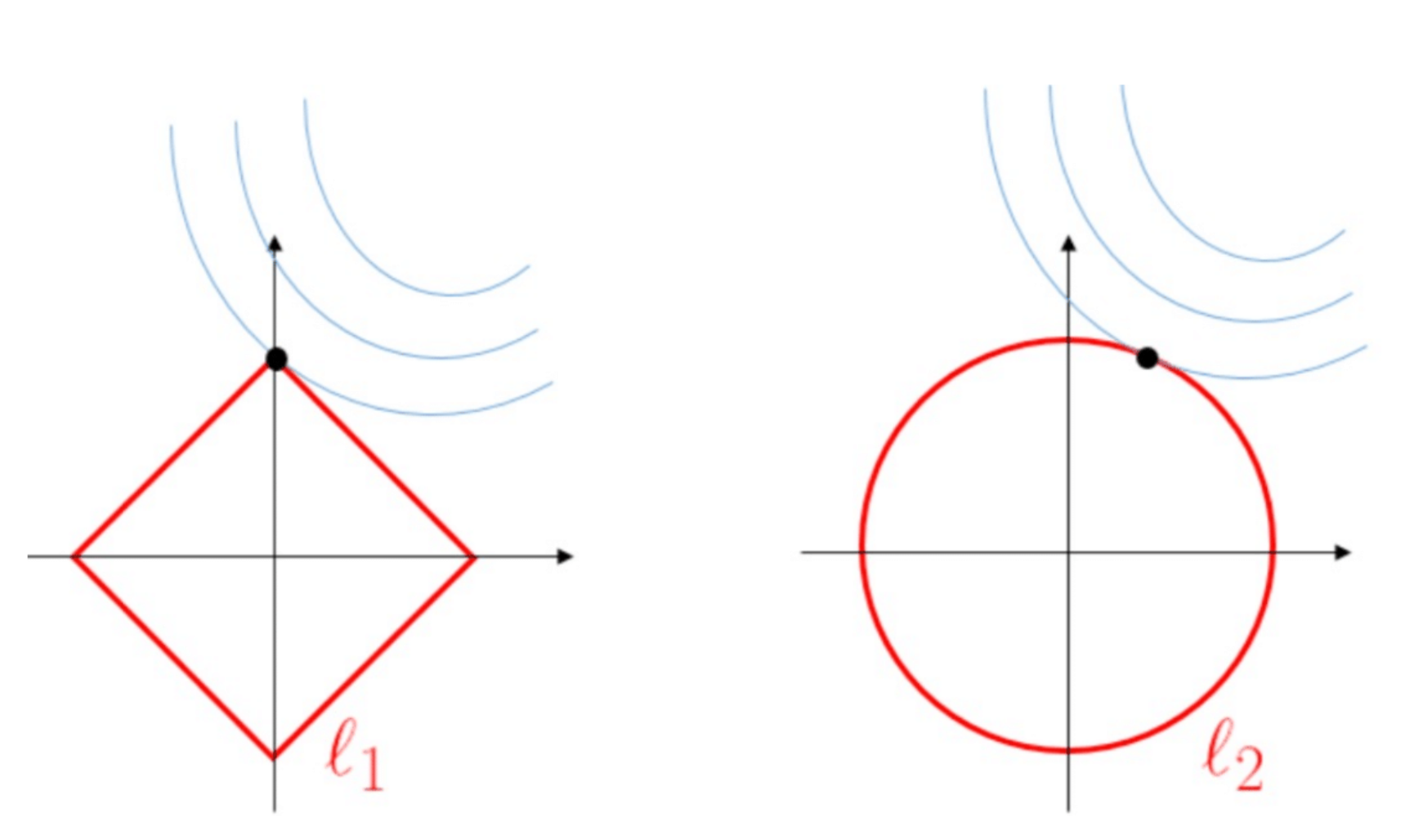
Weight regularization
L1 norm
Objective = , we call it Lasso Regression
Gradient descent: More zeros in weights
L2 norm
Objective = , we call it Ridge Regression
Decay in weights:
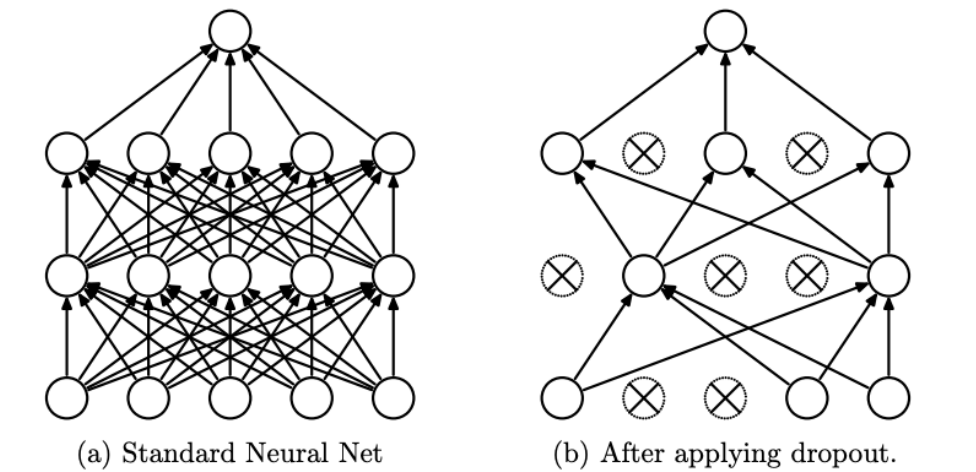
Dropout layer
Say dropout rate p.
During training, delete some intermediate output value with probability p or the weights times 1-p